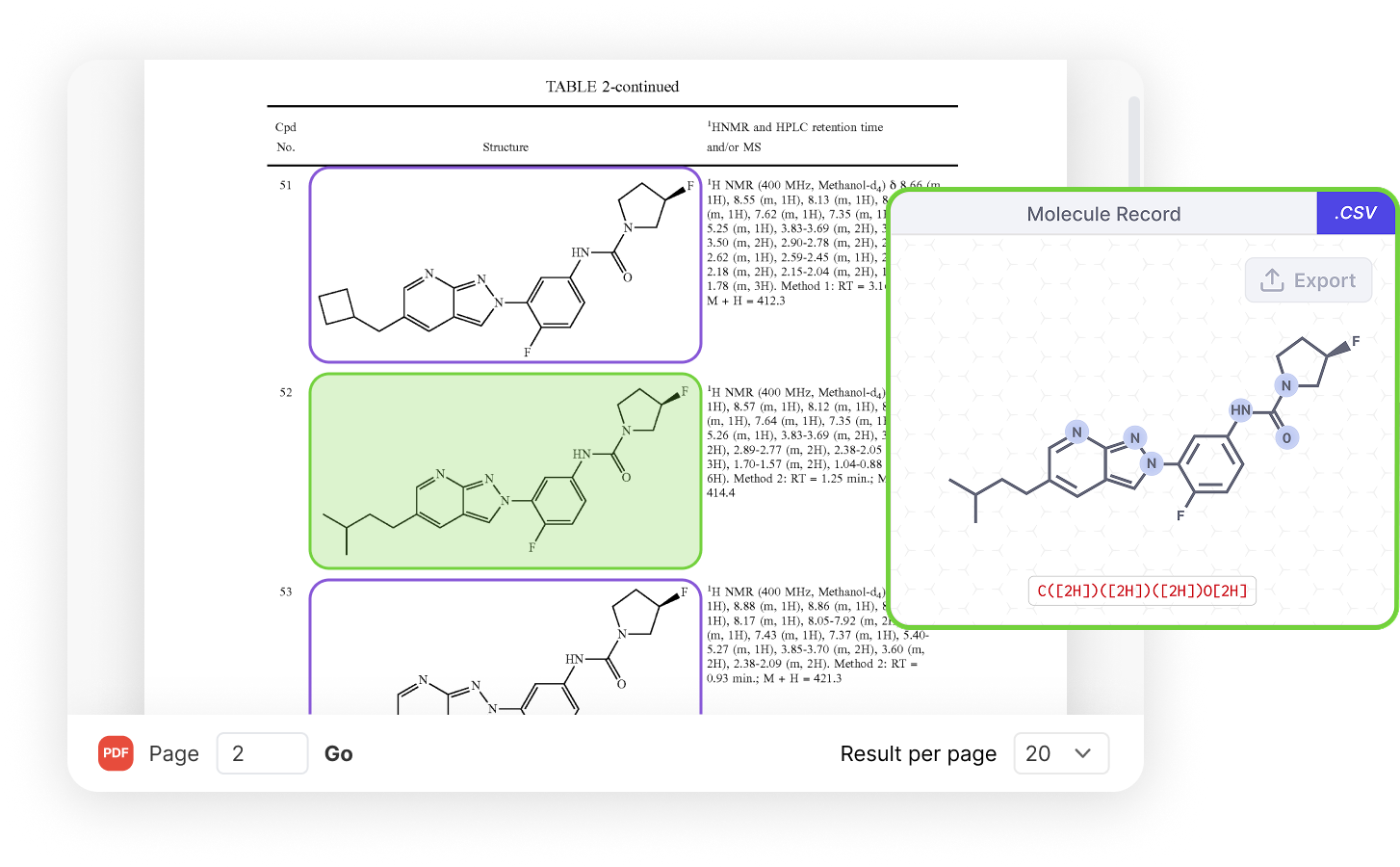
Upload any PDF to instantly convert embedded full molecule structures into verified SMILES strings. DO Patent’s extraction engine outperforms traditional OCR and GenAI sketch-to-SMILES tools — so you can spend time analyzing, not redrawing.
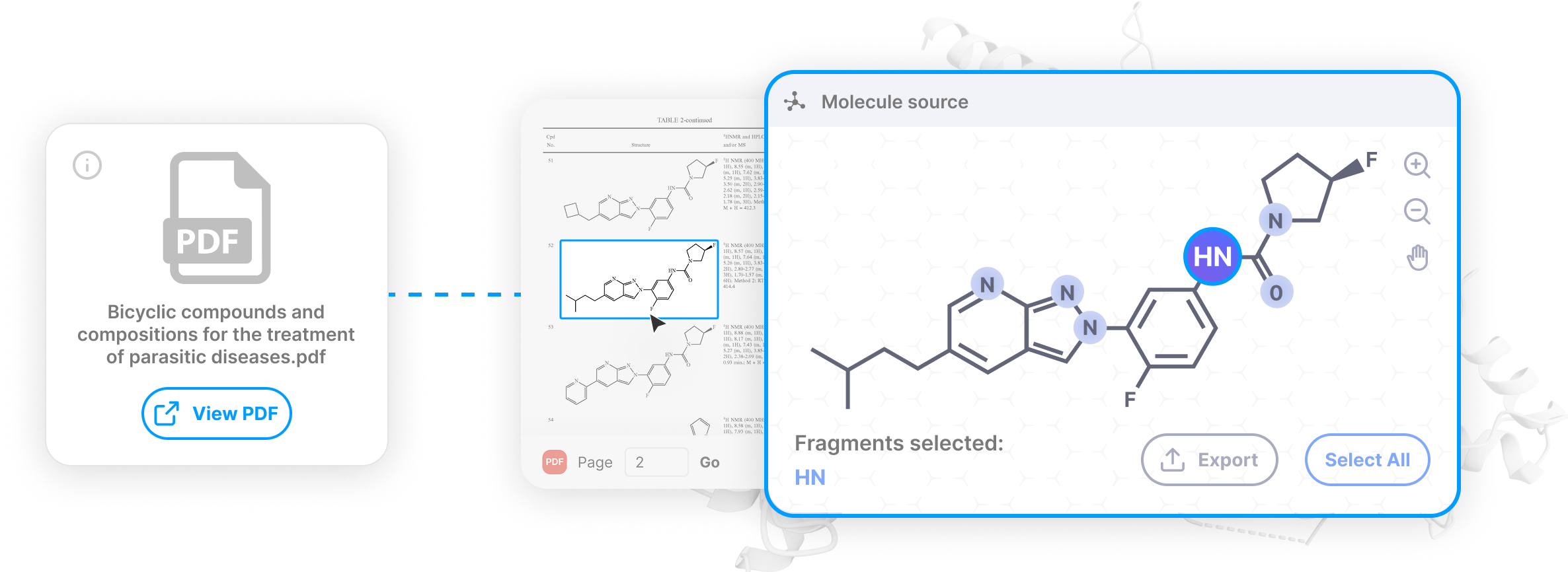
Each extracted molecule carries a confidence score so you can quickly spot and correct uncertain predictions. Medium-confidence structures are flagged with links to the exact source image and page, letting you verify and correct in seconds — full transparency for reproducible science.
Refine, edit, and export molecular data directly within the interface. Build unique SMILES datasets from sources that major databases can’t legally or technically aggregate — and keep full control over your competitive intelligence.
Extract, verify, and edit molecular structures directly from patents, publications, and other PDFs — greater than 98% full-molecule image data extraction accuracy.
Fast, accurate molecule extraction from PDFs — ideal for academic labs, independent researchers, and early-stage biotechs.
What you will get
Automatic full chemical structure extraction from PDFs
Integrated molecule visualizer and editor
Full data provenance and confidence
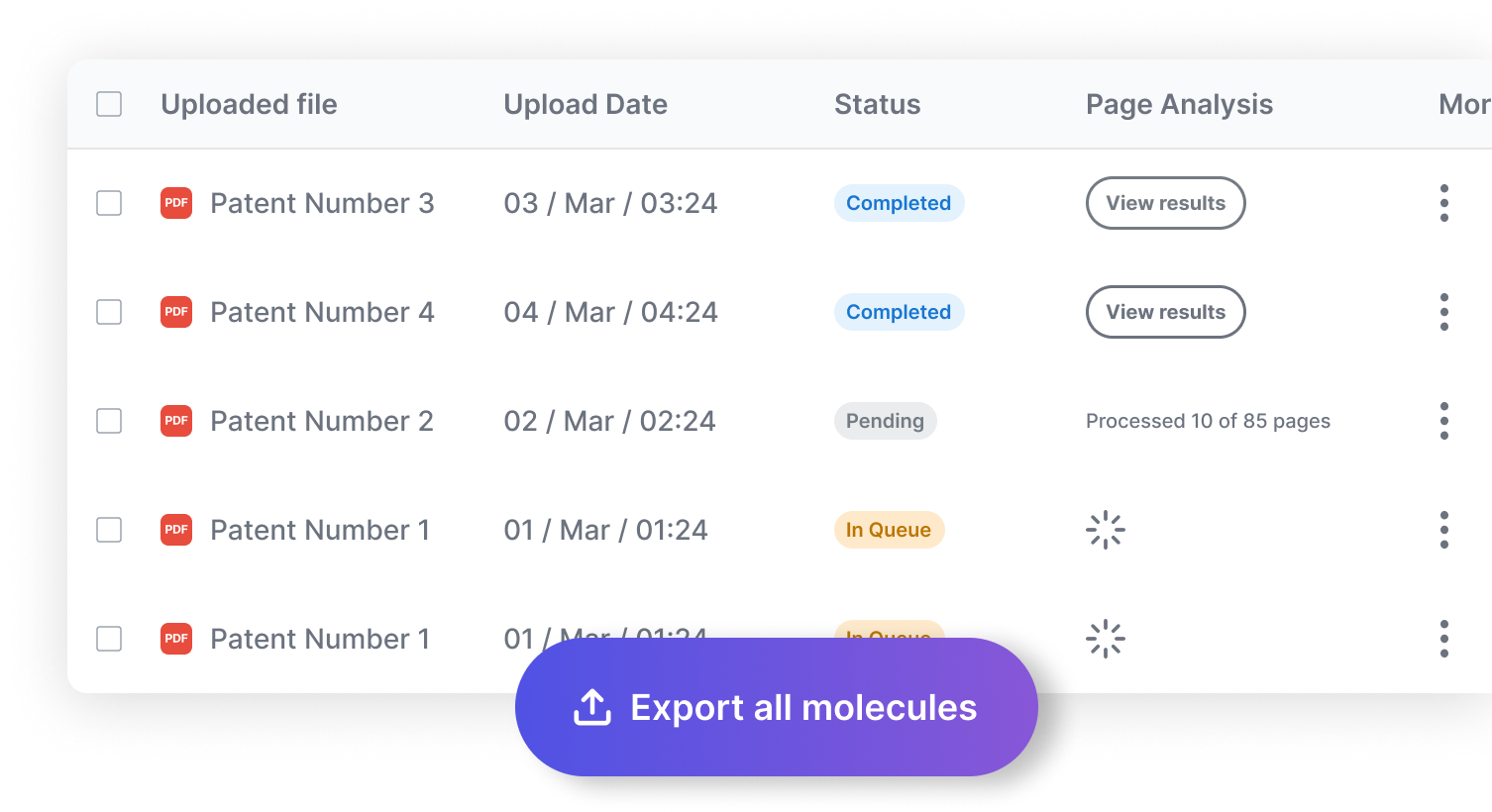
Bulk PDF uploads
Bulk SMILES export (Balto-ready)
Private, secure processing and storage

6000 Shoreline Ct. Ste 325, South San Francisco, CA 94080.
© 2023-{{year}} Deep Origin Inc. All rights reserved.
Deep Origin is a registered trademark of Deep Origin Inc.
We use statistics cookies to help us improve your experience of our website. By using our website, you consent to our use of cookies. To learn more, read our Privacy Policy and Cookie Policy.
.png)
.png)
.png)